







إعداد: مصطفى الزعبي
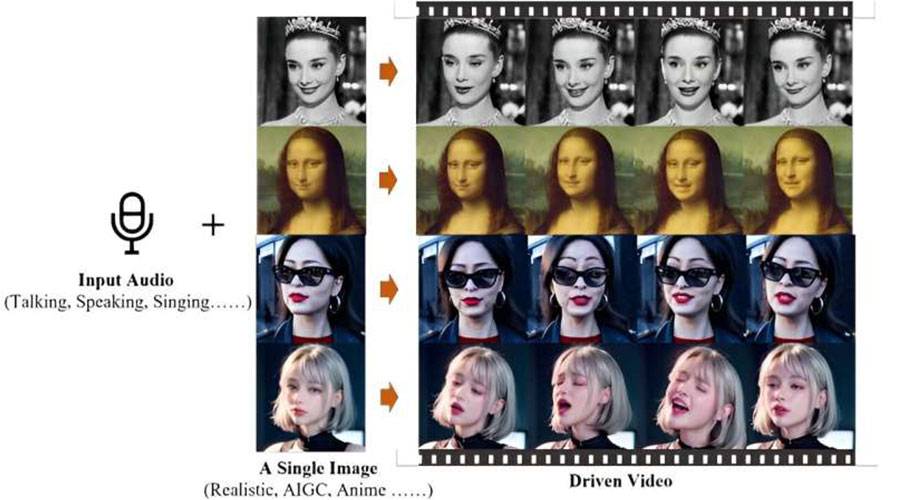
تمكن باحثون من معهد الحوسبة الذكية بالصين، من تحويل المسار الصوتي إلى فيديو لشخص يتحدث باستخدام صورة ثابتة بعد معالجة صورة الوجه واستخدامها، لإنشاء نسخة متحركة.
ويستخدم نظام الذكاء الاصطناعي المبتكر خوارزميات التعلم العميق لتحليل مدخلات الصوت، وإنشاء حركات شفاه واقعية تتوافق مع الكلمات المنطوقة، ومن خلال الاستفادة من قوة الشبكات العصبية، يمكن للنظام مزامنة الصوت بدقة مع التمثيل المرئي، ما يؤدي إلى إنشاء فيديو سلس للشخص الذي يتحدث.
وتخيل الإمكانات التي تفتحها هذه التكنولوجيا لمنشئي المحتوى وصانعي الأفلام ومحرري الفيديو، ومع القدرة على تحويل المسار الصوتي إلى فيديو، فإن إمكانية سرد القصص والتواصل لا حدود لها.
ولا يعمل نظام الذكاء الاصطناعي هذا على تبسيط عملية إنتاج الفيديو فحسب، بل يوفر أيضاً حلاً فعالاً من حيث الكلفة لإنشاء محتوى مرئي جذاب، ومن خلال التخلص من الحاجة إلى لقطات فيديو معقدة أو رسوم متحركة باهظة الثمن، يمكن للمستخدمين الآن إنشاء مقاطع فيديو جذابة، باستخدام صورة ثابتة ومسار صوتي فقط.
ومع استمرار تطور قدرات الذكاء الاصطناعي، يمكننا أن نتوقع رؤية المزيد من التطبيقات الرائدة في مجال التركيب السمعي والبصري، وأن القدرة على تحويل مسار صوتي إلى فيديو لشخص يتحدث هي مجرد بداية لما تقدمه هذه التكنولوجيا.





